This is the third in a series of blog posts about how I wrote and optimized VkColors, a small compute program written using Vulkan.
The previous post added a simple GPU implementation. This post will add several optimizations that improve performance massively.
Atomics
A 2X-3X speed up is nice, but I wanted to push the performance even further. I’ve read that people use atomics when they want to go fast, so I thought, why not try that?
Shader invocations are divided into work groups, typically 32 or 64 invocations per work group. This provides a natural boundary for dividing up the array. Instead of each shader invocation getting it’s own element to write to, each invocation in a work group shares the same memory location and writes to it using atomics. The GLSL function atomicMin is used to write the lowest score.
The results sent to the CPU still need to processed to find the lowest score. Using atomics just does some of the work for us on the GPU.
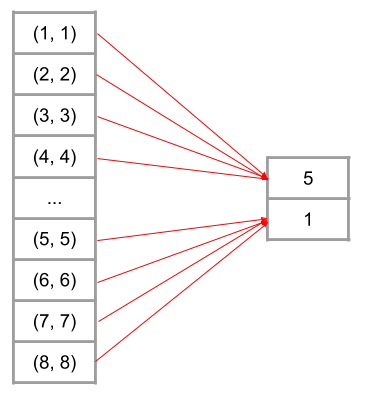
This provided no discernible change to the wave algorithm. It still runs at ~18,000 pps. For the coral algorithm, it provided a slight speed up to ~610 pps, from ~560. However using atomics means that these algorithms use 1/32 or 1/64 the amount of memory. This is possibly why there was a slight performance increase for the coral algorithm. Since the open set for coral becomes so large, the performance of the CPU cache has a large influence on performance (remember that the lowest score is selected on the CPU). Since atomics use so much less memory, there is less memory pressure and fewer cache misses.
Using atomics only had a small impact on the performance. However, the reduced memory footprint is critical for the next optimization.
Batching
Up until now, the algorithms score a single color per iteration. What if it scored multiple colors per iteration? That is, the algorithm writes scores for a two dimensional table, locations on one axis, colors on the other.
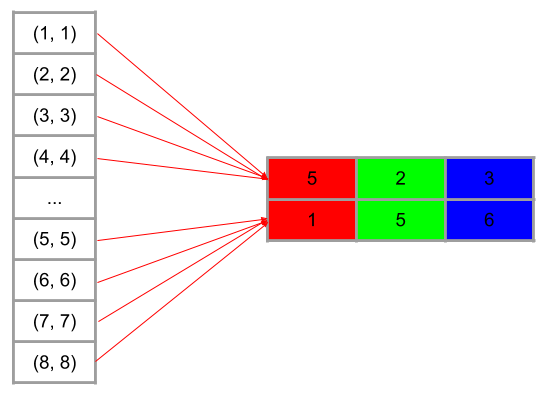
There are some problems that need to solved to allow this kind of batching. First, how many colors should be batched at once? There has to be an absolute maximum due to physical memory limits. But there also needs to be a relative maximum for the algorithms to produce an image that still looks good.
The number of colors batched at once can’t exceed the size of the open set, of course. But it also can’t match the size of the open set. The open set is not updated until after all colors for a batch are processed. Only some fraction of the open set can be filled in a single batch. Otherwise some pixels will be forced into a location that scored poorly, even if they would have found a better location in the next iteration, after updating the open set.
In practice, I’ve found that a batch size of about 64 works best. That means a relative batch size of between 1/1024 and 1/32 of the open set. This size batch offers good performance while still looking the same as Joszef’s algorithms. For example, with the coral algorithm the open set can reach a size of ~73,000. 73000 / 1024 gives us about 70 colors to batch at once.
The other problem with batching is, what happens if more than one color selects the same location? My solution is to choose one color to place at that location, while the others are recycled back into the queue. Those colors are placed in another batch at some later point.
The atomics are critical for reducing the amount of memory needed for batching. The largest usage of memory in VkColors is the output buffer that the compute shaders write to. It has to be large enough to hold the score for every location in the open set, which can be as large as the number of pixels in the image. For a 4096×4096 image, the size of the output buffer is:
4096 * 4096 * sizeof(Score) * maxBatchAbsolutemaxBatchAbsolute is the maximum size of the batch, which by default is 64. sizeof(Score) is 8. So the total size is:
4096 * 4096 * 8 * 64 == 8 GBVkColors double buffers the output buffer, so the total memory usage for the output buffers is 16 GB, easily exceeding the available memory on most GPUs. Atomics reduces the memory usage to 1/32 or 1/64 of that, which is 512 MB or 256 MB. This allows VkColors to run on any modern GPU.
Batching brings us an amazing speed up. The wave algorithm now runs in ~1.2 seconds, which is ~220,000 pps. That’s about 12X faster than the simple GPU implementation. The coral algorithm runs in ~14 seconds, which is ~18,000 pps, a 32X improvement. These algorithms now run about 24X and 100X faster than their CPU implementations, respectively.
These optimizations are in the v1.0 release of VkColors on GitHub.
Conclusion
I had a lot of fun writing this program. I got to use the Vulkan API for high performance computing and I got to use the async compute features of my GPU. I’d like to hear feedback about similar projects or about more optimizations that I could add.