This is the second in a series of blog posts about how I wrote and optimized VkColors, a small compute program written using Vulkan.
This post will examine the GPU implementations of VkColors. The algorithms are written as Vulkan compute shaders.
At the core of the algorithm, VkColors compares the scores of every location in the open set. For each iteration, the CPU implementation calculates scores on a single thread and only tracks the lowest score calculated so far. This uses O(1) memory space.
To run on the GPU, the algorithm must be parallelized. That means there is no “lowest score so far” since, in theory, every scoring calculation could run simultaneously. Instead, every score gets recorded into a separate entry in a large array. The memory usage must be O(n) where n is the size of the open set. Once the scores are recorded in the array, the lowest score can be selected.
The general architecture for the shaders is that each location is copied from the open set into a CPU array, and from the array into a Vulkan storage buffer to be accessed from the shader. The final result would be a struct of the form:
struct Score {
uint32_t score;
uint32_t index;
}
The index variable would be used to find the selected location in the CPU array. Then the color and the location would be used to send an update message to the render thread.
Premature Optimization
There are two distinct phases that can be parallelized, scoring and selecting. My first attempt to implement the algorithm used two compute shaders for these two phases. The first shader calculated the scores and wrote them into an array and the second shader used a parallel reduce min algorithm to select the lowest score.
The parallel reduce algorithm was implemented by creating a “pyramid” of arrays. The base of the pyramid was the array that the first phase wrote to. The other levels each had half the number of elements of the level below them. At the top, there would be room for a single element. Each invocation of the parallel reduce shader read two adjacent elements from level i and stored the lower score element in level i + 1. The lowest score would be stored at the top of the pyramid, and would be sent back to the CPU to finish the iteration.
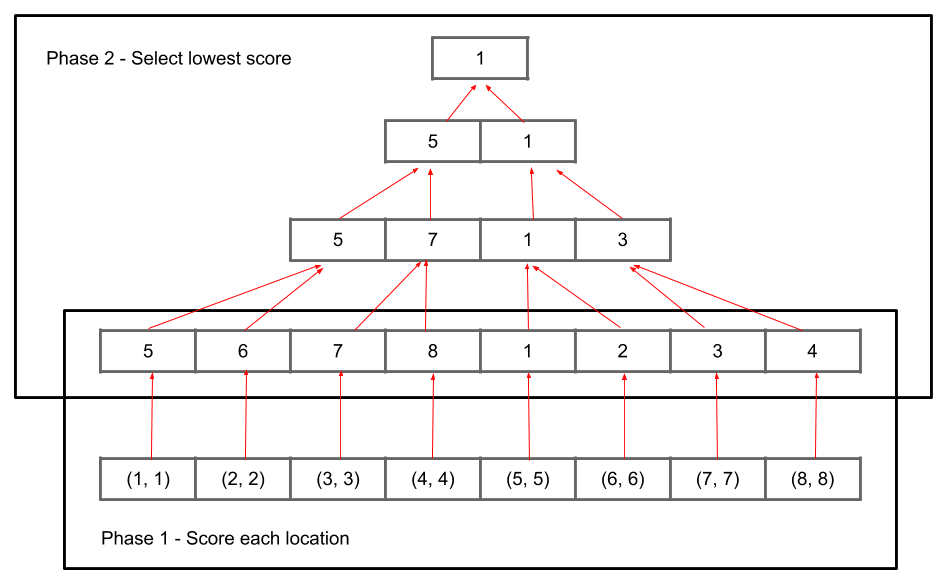
In theory, this would mean that both phases were parallelized and could be run on the GPU, all phase 1 invocations in parallel, then phase 2 invocations in parallel (each level separately). In practice, this resulted in a mere ~2,000 pps on the wave algorithm at the start, compared to ~9,000 pps from the CPU implementation. This was a pretty serious performance regression, so I considered this implementation to be a failure.
If you want to play with this version, it’s tagged as v0.1-pyramid in the git repo. However, this version is missing a lot of functionality that was added in later versions, like the command line options and even the coral shader.
Perhaps my implementation of the parallel reduce phase was bad. However the complexity of implementing it and the resultant performance led to me removing it from VkColors. Instead, I opted for a much simpler implementation.
A Much Simpler Implementation
Phase 1 would continue running on the GPU and the result array would be copied to CPU memory. Then phase 2 would run on the CPU. There is no pyramid now, just a simple loop to find the lowest score.
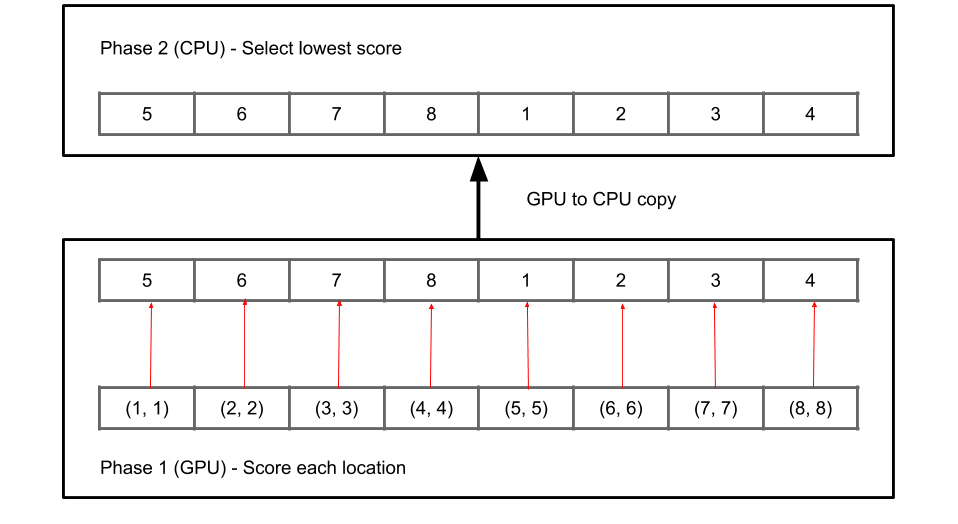
While the pyramid was removed, most of the infrastructure from the earlier attempt was kept. The compute shader to calculate the scores was kept and it’s interface was only slightly changed.
The work is submitted to the GPU on the generator thread. Unlike OpenGL, Vulkan allows API calls to be done on multiple threads as long as the user properly synchronizes access to certain objects. In this case, the VkQueue is protected with a mutex if the same queue is used for render and compute. On certain hardware (such as my RX 580), the user can access a dedicated, async compute queue, in which case no synchronization is needed at all.
The work is submitted to the GPU using double buffering, so phase 2 for frame i will run on the CPU while phase 1 for frame i + 1 is running on the GPU.
This simplification showed much better results than the pyramid. On the wave algorithm, it achieved an overall speed of ~18,000 pps, a 2X speedup. On the coral algorithm, it reached ~550 pps, a 3X speedup.
This version is tagged as v0.2-simple in the repo. Already, a simple GPU implementation has showed massive performance improvements. The next post will explore even larger performance gains.